
Each Proposal or Template has a general section for Proposal Settings which appears on the top right in the editor when first loaded or when no other element is selected. This section gives you the ability to manage defaults for all pages within the proposal.
Here you can manage:
- Headers
- Footers
- Page Numbering
- Page Margins and Padding
- Page Sizes (for PDF Output)

Page Design
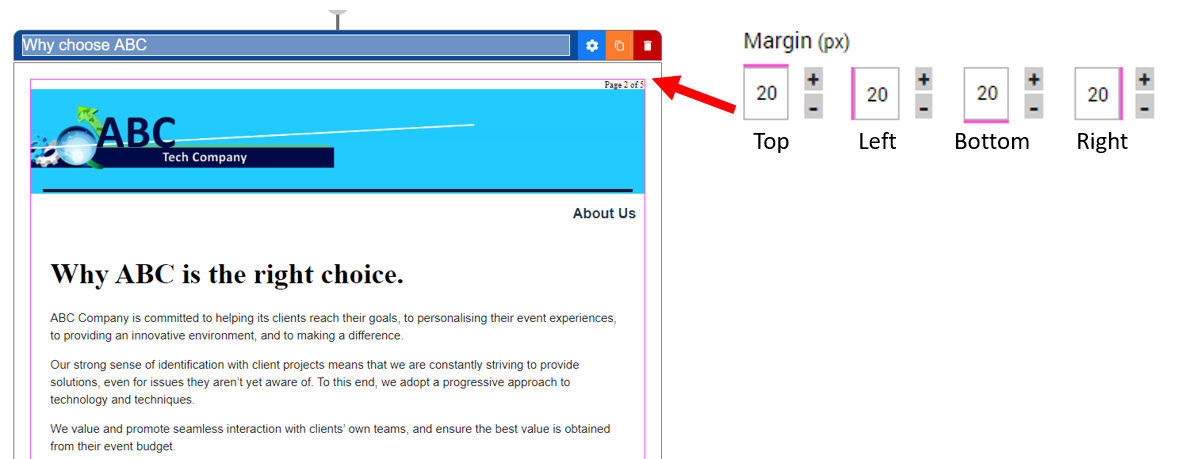
Margins
Set default page margins for the entire proposal.
Page Size

This is the default page size for PDF output. (Use PDF Preview button to ensure accuracy)
Page Numbering
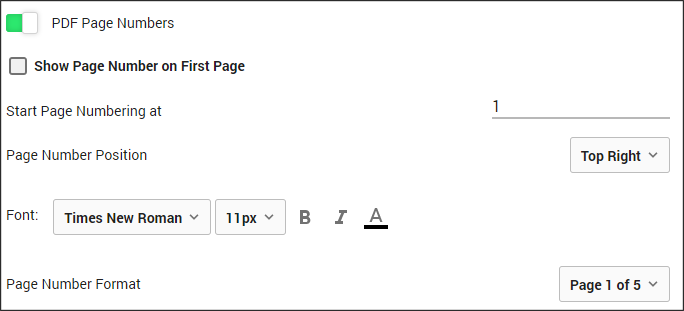
- Toggle on "PDF Page Numbers" to activate
- Select start page for numbering (Check box to show on page 1 or uncheck if it is a cover page)
- Select the position of the number - { Top / Bottom } - { Left / Middle / Right }
- Choose a font, size and color
- Select the Numbering Format - { 1 / Page 1 / Page 1 of 5 / 'Section Name - 1 }
Headers and Footers
Headers and Footers work identically as far as setup and formatting. If you create a header or footer in the Proposal Settings, it is used for the entire document unless you choose a different header or footer in the Section Settings (See below)
There are 3 types of Header/Footer formats
- Text - can have a background image (different from Text and Image which are separated)
- Image - Image only (No Text)
- Text and Image - 2 separate boxes on the same line. 1 text and 1 image
Once you select the format, the Header or Footer is activated and now shows a Settings Box for that element. Here is an overview of the settings for each.
Text Settings
The text settings are exactly the same as any text box used in the proposal builder.
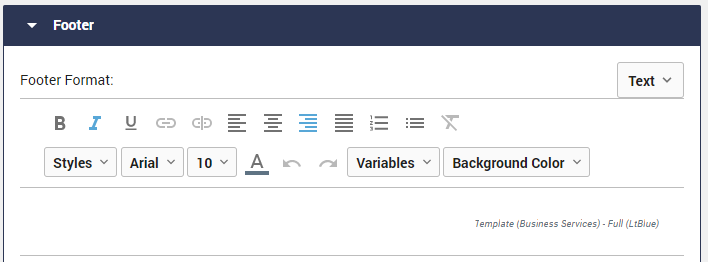
Enter text in the white space at the bottom of this box and format exactly how you want it to look.
You can paste into this box as well using windows copy and paste commands
(Ctrl+C and Ctrl+V/Ctrl + Shift/V)
You can also manage the Line Height (most common is 1.5 spacing)
The text box can also have a background image which includes settings to manage the size, link, and position.
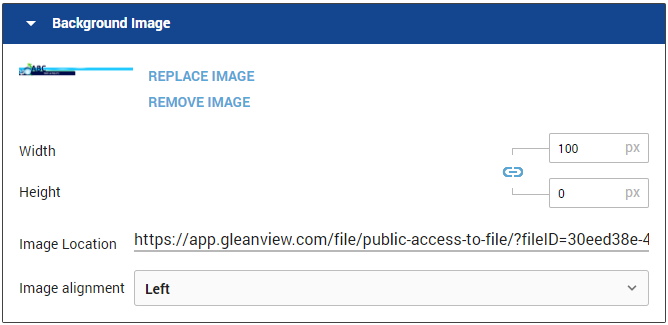
NOTE: If the image is larger than the text box, only part of the image will be displayed. This can be resolved by decreasing the image size or by adding spaces (hard returns) to the text box to expand it.
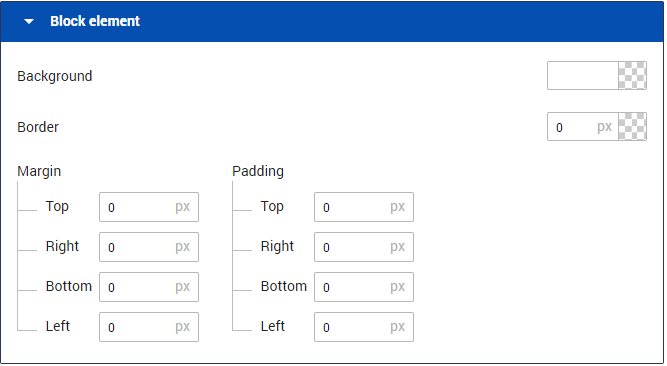
Block Element
As with all elements in the Proposal, the Block Element allows you to manage Margins, Padding, Border, and Background color for the entire rectangle (Block)
Margin generates white space around the outside of the block
Padding generates space inside the block which would be the same color as the background color
Section Settings
Clicking the Blue Cog at the top of any Section opens Settings specific to that section.

Each Settings Module (Page Design / Header / Footer) has default set as 'ON' to "Use Proposal Settings"
Turning this toggle "OFF" would allow you to then create a different setting that applies to this section only and ignores the default Proposal Settings {Headers / Footers / Numbering}

